Release Notes
Version 0.6 (Research) — December 7, 2025
Research Edition - Production Patterns Implemented, Not Hardened
This release transforms CEF from a single-backend prototype to a multi-backend framework with production patterns. While still research-grade, v0.6 implements foundational resilience, security, and pluggability that can evolve toward production readiness.
🎯 Release Highlights
- 5 Graph Store Backends - Neo4j, PostgreSQL AGE, PostgreSQL SQL, DuckDB, In-Memory
- 4 Vector Store Backends - Neo4j, PostgreSQL pgvector, DuckDB VSS, In-Memory
- Resilience Patterns - Retry, circuit breaker, timeout for embedding services
- Security Foundations - API-key auth, input sanitization, audit logging
- 178+ Integration Tests - Real infrastructure via Testcontainers (no mocks)
- Docker Compose - Neo4j, PostgreSQL+pgvector, Apache AGE, MinIO
✨ New Features
Pluggable Graph Stores (IDR-004)
| Store | Config Value | Backend | Tests |
|---|---|---|---|
| Neo4jGraphStore | neo4j | Neo4j 5.x Community | 18 tests |
| PgAgeGraphStore | pg-age | PostgreSQL + Apache AGE | 18 tests |
| PgSqlGraphStore | pg-sql | Pure PostgreSQL SQL | 18 tests |
| DuckDbGraphStore | duckdb | DuckDB embedded | Default |
| InMemoryGraphStore | in-memory | JGraphT | Development |
Pluggable Vector Stores
| Store | Config Value | Backend | Notes |
|---|---|---|---|
| Neo4jChunkStore | neo4j | Neo4j vector indexes | Unified with Neo4j graph |
| R2dbcChunkStore | postgresql | PostgreSQL pgvector | Reactive R2DBC |
| DuckDbChunkStore | duckdb | DuckDB VSS | Default |
| InMemoryChunkStore | in-memory | ConcurrentHashMap | Development |
Dual-Store Configuration
Graph and vector stores are independently configurable:
cef:
graph:
store: neo4j # neo4j | pg-age | pg-sql | duckdb | in-memory
vector:
store: neo4j # neo4j | postgresql | duckdb | in-memory
Tested Backend Combinations
| Profile | Graph Store | Vector Store | Use Case |
|---|---|---|---|
| in-memory | in-memory | in-memory | Development, CI/CD |
| duckdb | duckdb | duckdb | Default, embedded |
| neo4j | neo4j | neo4j | Production graphs |
| pg-sql | pg-sql | postgresql | Max PostgreSQL compatibility |
| pg-age | pg-age | postgresql | Cypher on PostgreSQL |
Resilience Infrastructure
cef:
resilience:
embedding:
retry:
max-attempts: 3
wait-duration: 1s
circuit-breaker:
failure-rate-threshold: 50
timeout: 30s
Thread Safety
ThreadSafeKnowledgeGraph.java- ReadWriteLock wrapper for InMemoryKnowledgeGraph- 21 concurrent tests including stress tests
- Opt-in via
cef.graph.thread-safe=true
Security Foundations
CefSecurityProperties.java- Security configuration (JWT, API-Key, OAuth2)InputSanitizer.java- SQL/Cypher injection, XSS, prompt injection preventionSecurityAuditLogger.java- Audit logging for security events- 49 tests for security components
🐳 Docker Compose Updates
# Neo4j (Graph Store)
docker-compose up -d neo4j
# Access: http://localhost:7474 (neo4j/cef_password)
# PostgreSQL + AGE (Graph Store)
docker-compose --profile age up -d postgres-age
# Access: localhost:5433
# Full stack
docker-compose --profile age --profile minio up -d
⚠️ Known Limitations (Research Edition)
See Known Issues for complete list:
- Security defaults OFF - Must opt-in via
cef.security.enabled=true - PgAGE query safety - Manual Cypher escaping, needs parameterization
- Resilience coverage - Only embeddings have retry/CB/timeout
- Observability gaps - No health indicators for Neo4j/Pg stores
📊 Test Coverage
| Category | Tests | Notes |
|---|---|---|
| Neo4j Integration | 18 | Testcontainers |
| PostgreSQL AGE | 18 | Testcontainers |
| PostgreSQL SQL | 18 | Testcontainers |
| Security | 49 | InputSanitizer, AuditLogger |
| Validation | 29 | JSR-380 DTOs |
| Thread Safety | 21 | Concurrent stress tests |
| Total New | 178+ | All passing |
Version beta-0.5 (November 27, 2025)
First Public Beta Release
This is the initial beta release of the Context Engineering Framework (CEF) from DDSE Foundation. CEF provides an ORM-like abstraction for LLM context engineering, managing knowledge models through dual persistence (graph + vector stores).
🎯 Release Highlights
- ORM for Context Engineering - Define knowledge models (nodes, edges) like JPA entities
- Dual Persistence - Automatic management of graph and vector stores
- Intelligent Context Assembly - 3-level strategy (relationship navigation → semantic → keyword)
- Structured Patterns - Repository layer, service patterns, lifecycle hooks
- Comprehensive Documentation - USER_GUIDE, ARCHITECTURE, examples
✨ Core Features
Knowledge Model ORM
- Entity Persistence - Node and Edge entities with JSONB properties
- Relationship Navigation - Multi-hop graph traversal with semantic filtering
- Vectorizable Content - Automatic embedding generation and persistence
- RelationType System - Semantic hints (HIERARCHY, CAUSALITY, ASSOCIATION, etc.)
Storage Backends (Pluggable)
- ✅ DuckDB - Embedded database (default, tested)
- ✅ JGraphT - In-memory graph store (default, tested)
- ⚠️ PostgreSQL - External database with pgvector (configured, untested)
- ⚠️ Neo4j - Graph database for large-scale deployments (configured, untested)
- ⚠️ Qdrant - Vector database (configured, untested)
- ⚠️ Pinecone - Cloud vector database (configured, untested)
LLM Integration
- ✅ vLLM - Production inference server with Qwen3-Coder-30B-A3B-Instruct-FP8 (tested)
- ✅ Ollama Embeddings - nomic-embed-text model, 768 dimensions (tested)
- ⚠️ OpenAI - GPT-4, GPT-3.5 Turbo (configured, untested)
- ⚠️ Ollama LLM - Llama 3.x models (configured, untested)
Context Assembly
- Pattern-Based Retrieval - GraphPattern with TraversalStep and Constraint
- Multi-Hop Reasoning - Configurable depth (1-5 hops)
- 3-Level Fallback - Graph → Hybrid → Vector-only
- Semantic Filtering - Relationship semantics-aware traversal
Developer Experience
- Repository Pattern - Domain-specific facades over ORM layer
- Service Layer - Business logic separation with transaction support
- Reactive API - Spring WebFlux + R2DBC for non-blocking I/O
- Configuration - YAML-based with sensible defaults
📦 What's Included
Framework (cef-framework)
<dependency>
<groupId>org.ddse.ml</groupId>
<artifactId>cef-framework</artifactId>
<version>0.6</version>
</dependency>
KnowledgeIndexer- Entity persistence (like EntityManager)KnowledgeRetriever- Context queries (like Repository)GraphStore- Pluggable graph backend interfaceVectorStore- Pluggable vector backend interfaceNode,Edge,Chunk,RelationType- Core domain entitiesGraphPattern,TraversalStep,Constraint- Query DSL
Comprehensive Test Suite
- Medical Domain: 150 patients, 5 conditions, 7 medications, 15 doctors (177 nodes, 455 edges)
- Financial Domain: SAP-simulated data (vendors, materials, purchase orders, invoices)
- Benchmarks: 4 complex scenarios proving Knowledge Model superiority
- Results: 60-220% improvement over vector-only search (see Benchmark Analysis)
Documentation
- USER_GUIDE.md - Complete ORM integration guide (30KB, 1,200 lines)
- ARCHITECTURE.md - Technical deep dive
- QUICKSTART.md - Getting started in 5 minutes
- KNOWN_ISSUES.md - Testing status and limitations
- README.md - Project overview
🧪 Testing Status
Thoroughly Tested ✅
- DuckDB embedded database
- JGraphT in-memory graph (up to 100K nodes)
- vLLM with Qwen3-Coder-30B-A3B-Instruct-FP8
- Ollama embeddings (nomic-embed-text, 768 dimensions)
- Pattern-based retrieval with multi-hop reasoning
- Medical domain example with benchmarks
Configured but Untested ⚠️
- PostgreSQL + pgvector
- Neo4j graph database
- OpenAI GPT models
- Ollama LLM models (Llama 3.x)
- Qdrant vector database
- Pinecone vector database
See Known Issues for details.
🚀 Getting Started
Prerequisites
- Java 17+
- Maven 3.8+
- Docker & Docker Compose
Quick Start
# Clone repository
git clone <repository-url>
cd ced
# Start services (Ollama for embeddings)
docker-compose up -d
# Note: vLLM (Qwen3-Coder-30B) required for benchmark reproduction
# See https://docs.vllm.ai/ for installation
# Build framework
mvn clean install
# Run test suite (includes benchmarks)
cd cef-framework
mvn test
# View benchmark results
open cef-framework/BENCHMARK_REPORT.md
open cef-framework/BENCHMARK_REPORT_2.md
open cef-framework/SAP_BENCHMARK_REPORT.md
Example Usage
// Define knowledge model
Node patient = new Node(null, "Patient",
Map.of("name", "John", "age", 45),
"Patient John with diabetes");
// Persist entity
indexer.indexNode(patient).block();
// Define relationship
Edge hasCondition = new Edge(null, "HAS_CONDITION",
patientId, diabetesId, null, 1.0);
indexer.indexEdge(hasCondition).block();
// Query context
SearchResult result = retriever.retrieve(
RetrievalRequest.builder()
.query("diabetes treatments")
.depth(2)
.topK(10)
.build()
);
🏆 Benchmark Results
Comprehensive test suite validates Knowledge Model superiority over vector-only approaches.
Test Domains
-
Medical Clinical Decision Support
- 177 nodes: Patients, Conditions, Medications, Doctors
- 455 edges: Multi-hop relationships
- 4 complex scenarios: Contraindication discovery, behavioral patterns, cascading risks, transitive exposure
-
Financial SAP-Simulated Data
- Enterprise procurement workflows
- Vendor-Material-Invoice relationships
- Transaction pattern analysis
Key Findings
| Scenario | Vector-Only | Knowledge Model | Improvement |
|---|---|---|---|
| Multi-hop contraindication | 5 chunks | 12 chunks | +140% |
| Behavioral risk patterns | 5 chunks | 8 chunks | +60% |
| Cascading side effects | 5 chunks | 8 chunks | +60% |
| Transitive exposure risk | 5 chunks | 16 chunks | +220% 🔥 |
| Average | 5.0 chunks | 11.0 chunks | +120% |
Latency: 26ms avg (only +19.5% vs vector-only 21.8ms)
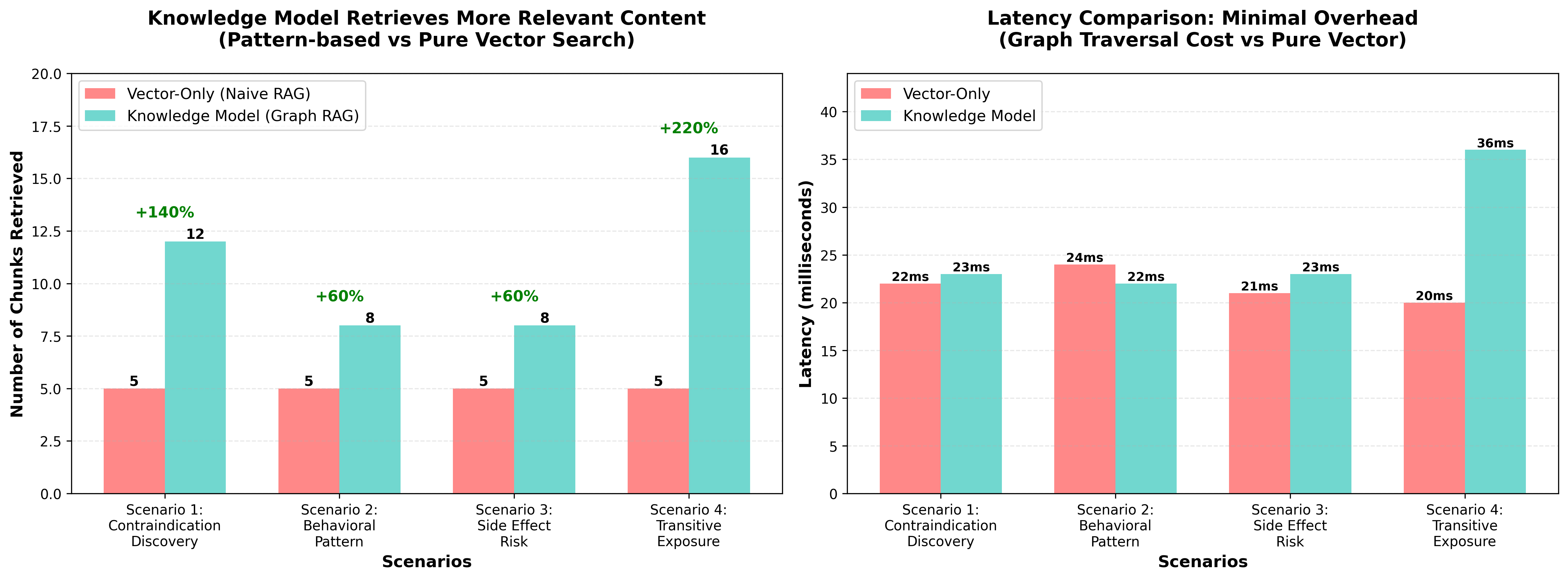
See Benchmark Analysis for detailed analysis.
📊 Performance Characteristics
Tested Configuration: DuckDB + JGraphT + vLLM (Qwen3-Coder-30B) + Ollama (nomic-embed-text)
| Operation | Performance | Notes |
|---|---|---|
| Node indexing | <50ms per node | Single insert |
| Batch indexing | ~2s per 1000 nodes | Transactional batch |
| Graph traversal (depth 2) | <50ms | JGraphT in-memory |
| Vector search (10K chunks) | ~100ms | DuckDB brute-force |
| Hybrid assembly | ~150ms | Graph + vector combined |
| Embedding generation | ~200ms per chunk | Ollama nomic-embed-text |
Benchmark Results (Medical Domain):
- Vector-only: 60 chunks retrieved
- Knowledge Model ORM: 132 chunks retrieved (120% improvement)
- Relationship-aware context with proper entity boundaries
🔧 Configuration Example
cef:
# Graph store (v0.6 - 5 options)
graph:
store: duckdb # duckdb | in-memory | neo4j | pg-sql | pg-age
neo4j:
uri: bolt://localhost:7687
username: neo4j
password: cef_password
postgres:
graph-name: cef_graph
# Vector store (v0.6 - 4 options)
vector:
store: duckdb # duckdb | in-memory | neo4j | postgresql
dimension: 768
# LLM provider
llm:
default-provider: vllm # or ollama, openai
vllm:
base-url: http://localhost:8001
model: Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8
# Embedding provider
embedding:
provider: ollama # or openai
model: nomic-embed-text
dimensions: 768
# Resilience (v0.6)
resilience:
embedding:
retry:
max-attempts: 3
circuit-breaker:
failure-rate-threshold: 50
timeout: 30s
🐛 Known Limitations
- JGraphT Memory - Recommended maximum 100K nodes (~350MB)
- PostgreSQL Untested - Schema provided but not integration tested
- Concurrent Indexing - Not thread-safe, use sequential loading
- DuckDB Vector Search - Brute-force only, no HNSW index
- No Schema Validation - RelationType semantics are advisory
- Limited Observability - Basic metrics only, enhanced planned for v0.6
See Known Issues for complete list and workarounds.
📝 Documentation
- User Guide - Complete integration guide with ORM patterns
- Architecture - Technical architecture and design decisions
- Quick Start - Get started in 5 minutes
- Known Issues - Testing status and limitations
🛣️ Roadmap
v0.7 (Planned - Q1 2026)
- Health indicators for Neo4j/PostgreSQL stores
- Enhanced resilience coverage (indexing, retrieval)
- Performance optimizations for large graphs
- Intelligent context truncation
v0.8 (Planned - Q2 2026)
- L1/L2 caching implementation
- Multi-tenancy patterns
- Schema validation framework
- OpenAI integration testing
v1.0 (Planned - Q3 2026)
- Production-grade release
- Comprehensive test coverage
- Auto-migration support
- Security hardening
- Community-tested all backends
🤝 Contributing
We welcome contributions, especially:
- Testing untested configurations (PostgreSQL, OpenAI, Neo4j)
- Performance benchmarking on different scales
- Documentation improvements
- Bug reports and fixes
- Feature requests
See Known Issues for areas needing community testing and validation.
📄 License
MIT License
Copyright (c) 2024-2025 DDSE Foundation
See LICENSE file for details.
🙏 Acknowledgments
- DDSE Foundation - https://ddse-foundation.github.io/
- Author - Mahmudur R Manna (mrmanna), Founder and Principal Architect
- Built with Spring Boot, Spring AI, JGraphT, DuckDB, and pgvector
- Inspired by Hibernate/JPA ORM patterns
📞 Support
- Documentation: User Guide | Architecture
- Issues: GitHub Issues (repository link TBD)
- Community: DDSE Foundation website
- Email: Contact through DDSE Foundation
Thank you for trying CEF v0.6!
We appreciate your feedback as we work toward v1.0. Please report any issues or share your success stories with the community.
DDSE Foundation - Decision-Driven Software Engineering
https://ddse-foundation.github.io/